I just got back from tonight's Agile Bazaar meeting. Making the decision to go or not was pretty difficult. On the one hand there was an offer to have free beer and pizza and watch the season premier of Lost in HiDef after having been deprived of Lost for so long. On the other hand was driving an hour out of my way for the opportunity to hear Mary Poppendieck give a talk on compensation. So of course, I went to hear what Mary had to say.
She told us it was her first version of the talk. There were some rough edges, but it was well worth the trip. It was a fascinating review of the various forms of incentive-based compensation and performance appraisals. The one area of difficulty for me was realizing that Mary is not actually opposed to different levels of compensation for different individuals (which was what I thought she was saying), but rather some of the traditional methods for determining individual compensation.
Thinking about compensation models is not something I do every day, so I'm not going to attempt to summarize Mary's talk. But if you have a chance to attend Mary's talk on this subject, I highly recommend it. Even if you disagree with her points, it will expose some of the assumptions that you might not have even realized you were making and give you some new ways of thinking about compensation.
I'm not sure if this was a point that Mary was making or not, but my biggest take-away was that one of the most natural links between Agile and compensation is to have at least some amount of link between the monetary performance of the product that an Agile team produces and that team's compensation. One of the hallmarks of Agile is rapid feedback. If one of the best ways to have people work on the right things is to make sure they know what the right things are, isn't the surest measure of "the right thing" the success of the end product rather than arbitrary measurements that are disconnected from product success?
The next meeting will be a talk by Steve Berczuk about the connection between developer workspaces and Agile development. Details when I have 'em.
Thursday, January 31, 2008
Sunday, January 27, 2008
Scaling Agile and Stand-up Meetings
In the "ask away" section Matt poses the following question:
Scaling Agile
At a high level, it seems like your question is: “how do you scale Scrum?” In my experience, scaling is mostly independent of methodology. There are some Agile practices which can limit scalability, but luckily those practices are not required to get the primary benefits of Agile development. The practices which limit scaling are: relying on collocation and using 3x5 cards to the exclusion of other methods for storing and distributing project information. Other than that, what did the 200+ person do to scale prior to Scrum? Whatever it was, there is no reason that I can see to prevent them from scaling using those methods. Speaking specifically about Scrum, the Scrum-of-Scrums is the method recommended by Ken Schwaber for scaling project information flow.
Another area which is often a problem with scaling in general is the frequent integration required by the short iterations. For that you may consider Multi-Stage Continuous Integration.
Stand Up Meetings
As for the stand-up meetings, those are mandatory in Scrum. I don’t happen to agree with that requirement, but let’s hold that thought for a moment.
First, let’s take a look at the expense side of the Scrum meetings. First, people have to get to it. You have to wait until everybody is there. And then you have to get back to your computer. Scrum discusses how to minimize this time, but practically speaking, there is more overhead than just the ideal 15 minute meeting. If you are at a larger company, somebody has to book the room and let people know where it is. Let’s call the cost of the meeting 20 minutes per person. If you have 12 people in a Scrum, that’s 4 person hours per day. That’s the equivalent of half of a person. Those Scrum meetings had really better be worth it!
If they are worth it, then there is actually no problem and if somebody going to Scrum-of-Scrums has a personal dislike of meetings, even when they provide value, then perhaps somebody else should be doing the Scrum-of-Scrums.
Now let’s take a hard look at the stand-up meeting itself. One of the basic ideas of Agile (and Lean) is continual self improvement. If the value of the meeting exceeds the cost, then there’s no problem with the meetings, especially if they are eliminating other meetings. If the Scrum meeting is the only remaining status meeting, that seems like a good thing. However, continuous improvement means we’re never satisfied. Now that you are down to just the one meeting, you should still ask the question: “is it providing more value than the cost? Is there a better way?”
What is the purpose of the Scrum? To quickly find out if people are getting their assigned work done and if not why not. Isn’t it more efficient to do that via e-mail, IM, an issue tracking system, or other means? Someone might say “but the socialization aspect is worthwhile.” Ok, so why not separate the two? By all means let's have some social activities, but that's not a good reason for having a status meeting.
Or perhaps the Scrum is needed because otherwise folks wouldn’t complete their work, or people wouldn’t speak up when they run into an impediment. In that case the Scrum isn’t a solution at all. For instance, perhaps somebody isn’t completing their work because they don’t like it, but the constant peer pressure of the standup meeting is goading them into completing their work anyway. So then the real problem is lack of job satisfaction or low morale or something along those lines. Until you fix that problem, the standup is just acting as a band-aid for an underlying management problem. If you find that having standup meetings from time to time helps to expose management problems, then by all means have the meeting(s), find the problem(s), but don't have the meetings just for the sake of having them!
Short Iterations
One more thought on this topic: the real measure of project status and health is having an increment of shippable value at the end of every iteration. A standup will only expose problems that are on people’s minds, but the forcing function of the increment of shippable value is where you will get the true picture of how things are going. A one month iteration interval is good, but if you can get it down to 2 weeks or even 1 week, that will do far more to expose real problems than a standup will.
Speaking of short iterations, IMHO that’s really the number one thing which makes Agile scale better than traditional development. It is much easier to manage and coordinate large multi-team projects when the scope of everything is constantly focused on one month iterations (sprints). Of course, it may seem more difficult at times, but that is often due to the fact that problems are much more apparent and can’t “hide out” like they do in long iterations.
In summary, experiment and see what works for your particular situation, but always be on the lookout for opportunities for process improvement. Don’t do things by rote, demand that all activities provide real value.
Have a question on Agile or Software Development? Please visit the "ask away" section.
We're doing Scrum on a 10-12 person team (depending on what the DBAs are working on at the moment) and one of the more interesting problems I've been talking about with people is how to scale the process. I have a friend on a 200+ person project and they do Scrum-of-Scrums every day so one person from each "lower level" scrum team goes to another scrum meeting and so on up to the meeting with all the main project heads. This sometimes ends up taking 2 hours out of people's days if they have to go to a bunch of the scrum-of-scrums. What are your feelings on scaling Agile processes up to larger teams? Do you sacrifice somebody to be the "meeting person"? To me communication has always been the most important part of any Agile process, how do you keep that in large teams?
Scaling Agile
At a high level, it seems like your question is: “how do you scale Scrum?” In my experience, scaling is mostly independent of methodology. There are some Agile practices which can limit scalability, but luckily those practices are not required to get the primary benefits of Agile development. The practices which limit scaling are: relying on collocation and using 3x5 cards to the exclusion of other methods for storing and distributing project information. Other than that, what did the 200+ person do to scale prior to Scrum? Whatever it was, there is no reason that I can see to prevent them from scaling using those methods. Speaking specifically about Scrum, the Scrum-of-Scrums is the method recommended by Ken Schwaber for scaling project information flow.
Another area which is often a problem with scaling in general is the frequent integration required by the short iterations. For that you may consider Multi-Stage Continuous Integration.
Stand Up Meetings
As for the stand-up meetings, those are mandatory in Scrum. I don’t happen to agree with that requirement, but let’s hold that thought for a moment.
First, let’s take a look at the expense side of the Scrum meetings. First, people have to get to it. You have to wait until everybody is there. And then you have to get back to your computer. Scrum discusses how to minimize this time, but practically speaking, there is more overhead than just the ideal 15 minute meeting. If you are at a larger company, somebody has to book the room and let people know where it is. Let’s call the cost of the meeting 20 minutes per person. If you have 12 people in a Scrum, that’s 4 person hours per day. That’s the equivalent of half of a person. Those Scrum meetings had really better be worth it!
If they are worth it, then there is actually no problem and if somebody going to Scrum-of-Scrums has a personal dislike of meetings, even when they provide value, then perhaps somebody else should be doing the Scrum-of-Scrums.
Now let’s take a hard look at the stand-up meeting itself. One of the basic ideas of Agile (and Lean) is continual self improvement. If the value of the meeting exceeds the cost, then there’s no problem with the meetings, especially if they are eliminating other meetings. If the Scrum meeting is the only remaining status meeting, that seems like a good thing. However, continuous improvement means we’re never satisfied. Now that you are down to just the one meeting, you should still ask the question: “is it providing more value than the cost? Is there a better way?”
What is the purpose of the Scrum? To quickly find out if people are getting their assigned work done and if not why not. Isn’t it more efficient to do that via e-mail, IM, an issue tracking system, or other means? Someone might say “but the socialization aspect is worthwhile.” Ok, so why not separate the two? By all means let's have some social activities, but that's not a good reason for having a status meeting.
Or perhaps the Scrum is needed because otherwise folks wouldn’t complete their work, or people wouldn’t speak up when they run into an impediment. In that case the Scrum isn’t a solution at all. For instance, perhaps somebody isn’t completing their work because they don’t like it, but the constant peer pressure of the standup meeting is goading them into completing their work anyway. So then the real problem is lack of job satisfaction or low morale or something along those lines. Until you fix that problem, the standup is just acting as a band-aid for an underlying management problem. If you find that having standup meetings from time to time helps to expose management problems, then by all means have the meeting(s), find the problem(s), but don't have the meetings just for the sake of having them!
Short Iterations
One more thought on this topic: the real measure of project status and health is having an increment of shippable value at the end of every iteration. A standup will only expose problems that are on people’s minds, but the forcing function of the increment of shippable value is where you will get the true picture of how things are going. A one month iteration interval is good, but if you can get it down to 2 weeks or even 1 week, that will do far more to expose real problems than a standup will.
Speaking of short iterations, IMHO that’s really the number one thing which makes Agile scale better than traditional development. It is much easier to manage and coordinate large multi-team projects when the scope of everything is constantly focused on one month iterations (sprints). Of course, it may seem more difficult at times, but that is often due to the fact that problems are much more apparent and can’t “hide out” like they do in long iterations.
In summary, experiment and see what works for your particular situation, but always be on the lookout for opportunities for process improvement. Don’t do things by rote, demand that all activities provide real value.
Have a question on Agile or Software Development? Please visit the "ask away" section.
Thursday, January 24, 2008
Agile and Software Development Answers
Ask any question about Agile development or the process of software development in general and I'll do my best to answer it. If you'd like to see a post on a particular subject, let me know and I'll consider it.
In the meantime, there's a lot of information on Agile here: "Zero to Hyper Agile in 90 Days or Less" .
Please note that I will continue to remove all spam comments.
In the meantime, there's a lot of information on Agile here: "Zero to Hyper Agile in 90 Days or Less" .
Please note that I will continue to remove all spam comments.
Monday, January 21, 2008
The Chinese Finger Trap Part II: Architecture, Development, and QA
In Part I of this series I introduced the idea that traditional development is like a Chinese Finger Puzzle. Solutions to problems often make the problem worse instead of better. This post will cover two more areas that illustrate this phenomenon.
Future-Proof Architecture, Major Releases and Large Feature Sets
A common sentiment when using traditional development is that because it is so hard to redo architecture, because it takes so long to make changes, because it takes so long to produce a release, we had better get the architecture right the first time. We had better take into account all possibilities and eventualities. Since we are going to spend a long time on the architecture, we better plan to do a lot of features for the release. All of those features mean we need to take more variables into account and have an even more thoroughly thought out architecture. In a traditional project, the interplay between architecture, release timeframe, and feature set create a vicious cycle which tends to increase the scope of all three.
In an Agile project, the practices of short iterations and iterative design reinforce each other to keep the amount of architecture that is required as small and simple as possible yet no less than necessary. The product backlog and short iterations keep the feature set focused on those features which will produce the highest customer and market value instead of trying to build a product which takes into account all possible future requirements.
Read more about iterative design: "Designing Software is the Same as Predicting the Future."
Separation of Development and QA
A common pattern in traditional development is the separation of development and QA. Of course everybody always says that “QA is everybody’s job” and “you can’t test quality into a product” and “QA should be involved right from the start,” but what usually happens in practice is that QA occurs at the end. One contributor to this problem is that “during development” the product isn’t stable enough to test and you want to get the most bang for the buck out of your testing because it is so expensive to do and it takes so long to qualify a release. The natural result from these circumstances is the separation of development and QA which is constantly reinforced. Using traditional development patterns, all efforts to unify development and QA are inevitably defeated. Nobody is consciously trying to make it happen, it just happens.
But sometimes it is also on purpose. The separation of development and QA can feel “more honest.” Sometimes development doesn’t want QA to know what is going on because they are sure that they can catch up and fix things and then deliver something to QA which is good. But in order to get the benefits of QA without the help from the official QA folks, development ends up having to do QA themselves which reduces the time spent on development. In any case, traditional development practices tend to separate development and QA.
Agile practices do just the opposite, they tend to bring development and QA closer together. The writing of tests for a particular change is done either before the coding starts or during the coding, not in a separate phase at the end of all coding. Tests are run constantly using the practice of Continuous Integration. QA doesn’t have to wait until the traditional code-freeze to start the bulk of their work. This creates a positive feedback loop where QA gets to show its value on a regular basis, development spends less time fixing things at the last minute, QA learns more about the product, and development and QA become even closer.
Next: Short Iterations
Future-Proof Architecture, Major Releases and Large Feature Sets
A common sentiment when using traditional development is that because it is so hard to redo architecture, because it takes so long to make changes, because it takes so long to produce a release, we had better get the architecture right the first time. We had better take into account all possibilities and eventualities. Since we are going to spend a long time on the architecture, we better plan to do a lot of features for the release. All of those features mean we need to take more variables into account and have an even more thoroughly thought out architecture. In a traditional project, the interplay between architecture, release timeframe, and feature set create a vicious cycle which tends to increase the scope of all three.
In an Agile project, the practices of short iterations and iterative design reinforce each other to keep the amount of architecture that is required as small and simple as possible yet no less than necessary. The product backlog and short iterations keep the feature set focused on those features which will produce the highest customer and market value instead of trying to build a product which takes into account all possible future requirements.
Read more about iterative design: "Designing Software is the Same as Predicting the Future."
Separation of Development and QA
A common pattern in traditional development is the separation of development and QA. Of course everybody always says that “QA is everybody’s job” and “you can’t test quality into a product” and “QA should be involved right from the start,” but what usually happens in practice is that QA occurs at the end. One contributor to this problem is that “during development” the product isn’t stable enough to test and you want to get the most bang for the buck out of your testing because it is so expensive to do and it takes so long to qualify a release. The natural result from these circumstances is the separation of development and QA which is constantly reinforced. Using traditional development patterns, all efforts to unify development and QA are inevitably defeated. Nobody is consciously trying to make it happen, it just happens.
But sometimes it is also on purpose. The separation of development and QA can feel “more honest.” Sometimes development doesn’t want QA to know what is going on because they are sure that they can catch up and fix things and then deliver something to QA which is good. But in order to get the benefits of QA without the help from the official QA folks, development ends up having to do QA themselves which reduces the time spent on development. In any case, traditional development practices tend to separate development and QA.
Agile practices do just the opposite, they tend to bring development and QA closer together. The writing of tests for a particular change is done either before the coding starts or during the coding, not in a separate phase at the end of all coding. Tests are run constantly using the practice of Continuous Integration. QA doesn’t have to wait until the traditional code-freeze to start the bulk of their work. This creates a positive feedback loop where QA gets to show its value on a regular basis, development spends less time fixing things at the last minute, QA learns more about the product, and development and QA become even closer.
Next: Short Iterations
Sunday, January 20, 2008
Getting Your Fingers Caught in the Chinese Finger Trap of Traditional Development
One of the difficulties in moving to Agile development is that much of the “knowledge” that we have from decades of traditional development makes Agile seem counterintuitive. Part of this knowledge is embodied in habits, taboos, and ceremonies. There are things which we believe are facts in general which are actually only facts within the framework of traditional development. In effect, Agile is right in our blind spot.
Many of the practices of traditional development are actually accommodations for problems that only occur in a traditional project and thus are not necessary in an Agile project. We feel that we need these accommodations because they have always been there, but we need to recognize them for what they are in order to let go of them and embrace Agile development.
In traditional development, a frequent solution to many problems is adding more rigor, taking more time, adding more detail, and adding more policies and procedures. “This time we’ll do things right" is our frequent refrain. We believe the reason for problems last time was a lack of discipline and so there is a call for more discipline. This is analogous to the Chinese Finger Trap. The solution appears to be adding more policies and procedures (pulling harder on the finger trap), but in fact the solution is to simplify (pushing your fingers together.)
Tighter Policies and Procedures
In any development project, problems arise. They may be new problems or old problems. At some point, it will be decided to make a change in response to a problem. It may be that the change is to add a new policy or a new procedure. Whatever the change is, it will likely require additional effort. The effort is justified by the fact that the problem is addressed. It may be addressed by treating the symptoms or it may be addressed by removing the root cause of the problem. When it does in fact require additional effort and does not remove the root cause of the problem, you have now increased the overhead of all future projects. This overhead contributes to the complexity of future projects and can lead to additional problems and additional overhead.
The impact of any change to policy or procedure is difficult to gauge in a traditional project. There just aren’t enough opportunities for feedback and adjustment. In an Agile project, the practices of short iterations and one piece flow provide constant feedback and frequent opportunities for adjustment.
Tighter Requirements
How many times have you heard or thought something similar to: “The last time we didn’t get the requirements right, we better spend more time getting it right and get more details.” And what about the follow-on which probably isn’t said aloud: “Let’s make sure it is clear to everybody that we did the right thing and that nobody can point the finger at us and say that we didn’t do our job. Let’s make the requirements look as professional and complete as possible.”
Over time, these two sentiments produce a lot of boilerplate and CYA-style artifacts which only provide value after the fact when the finger-pointing starts. You can refer to the requirements and say “but see, we did what was asked of us.” So the value that is produced is that you can absolve yourself of blame. But nobody will pay you for that absolution and in fact you may lose opportunities because you didn’t satisfy the customer.
There are only four things which provide value in a software product: getting enough information from the customer to produce something which can then be used for further refinement, documenting how the software works just enough so that somebody can maintain it later and join the project now, providing software to the end user that they want, and getting paid for the software you produce.
Agile projects do use requirements, but only the absolute minimum required: no more and no less. The use of short iterations means that you will find and implement your customers' true requirements much faster so there is much less need for speculation and prediction. Requirements that turn out to be for things that customers don't actually need can be abandoned instead of elaborately detailed prior to the first customer feedback on working software.
For those that have auditing requirements, consider that if you have enough documentation for somebody to maintain your software then you should have an auditable “paper trail.” Conversely, if you don’t have an auditable paper trail, how can you expect to maintain your software or easily add a new team member?
There are many other areas of traditional development which contain Chinese Finger Traps.
Next: Chinese Finger Trap Part II: Architecture, Development, and QA.
Many of the practices of traditional development are actually accommodations for problems that only occur in a traditional project and thus are not necessary in an Agile project. We feel that we need these accommodations because they have always been there, but we need to recognize them for what they are in order to let go of them and embrace Agile development.
In traditional development, a frequent solution to many problems is adding more rigor, taking more time, adding more detail, and adding more policies and procedures. “This time we’ll do things right" is our frequent refrain. We believe the reason for problems last time was a lack of discipline and so there is a call for more discipline. This is analogous to the Chinese Finger Trap. The solution appears to be adding more policies and procedures (pulling harder on the finger trap), but in fact the solution is to simplify (pushing your fingers together.)
Tighter Policies and Procedures
In any development project, problems arise. They may be new problems or old problems. At some point, it will be decided to make a change in response to a problem. It may be that the change is to add a new policy or a new procedure. Whatever the change is, it will likely require additional effort. The effort is justified by the fact that the problem is addressed. It may be addressed by treating the symptoms or it may be addressed by removing the root cause of the problem. When it does in fact require additional effort and does not remove the root cause of the problem, you have now increased the overhead of all future projects. This overhead contributes to the complexity of future projects and can lead to additional problems and additional overhead.
The impact of any change to policy or procedure is difficult to gauge in a traditional project. There just aren’t enough opportunities for feedback and adjustment. In an Agile project, the practices of short iterations and one piece flow provide constant feedback and frequent opportunities for adjustment.
Tighter Requirements
How many times have you heard or thought something similar to: “The last time we didn’t get the requirements right, we better spend more time getting it right and get more details.” And what about the follow-on which probably isn’t said aloud: “Let’s make sure it is clear to everybody that we did the right thing and that nobody can point the finger at us and say that we didn’t do our job. Let’s make the requirements look as professional and complete as possible.”
Over time, these two sentiments produce a lot of boilerplate and CYA-style artifacts which only provide value after the fact when the finger-pointing starts. You can refer to the requirements and say “but see, we did what was asked of us.” So the value that is produced is that you can absolve yourself of blame. But nobody will pay you for that absolution and in fact you may lose opportunities because you didn’t satisfy the customer.
There are only four things which provide value in a software product: getting enough information from the customer to produce something which can then be used for further refinement, documenting how the software works just enough so that somebody can maintain it later and join the project now, providing software to the end user that they want, and getting paid for the software you produce.
Agile projects do use requirements, but only the absolute minimum required: no more and no less. The use of short iterations means that you will find and implement your customers' true requirements much faster so there is much less need for speculation and prediction. Requirements that turn out to be for things that customers don't actually need can be abandoned instead of elaborately detailed prior to the first customer feedback on working software.
For those that have auditing requirements, consider that if you have enough documentation for somebody to maintain your software then you should have an auditable “paper trail.” Conversely, if you don’t have an auditable paper trail, how can you expect to maintain your software or easily add a new team member?
There are many other areas of traditional development which contain Chinese Finger Traps.
Next: Chinese Finger Trap Part II: Architecture, Development, and QA.
Thursday, January 17, 2008
Advanced Multi-Stage Continuous Integration
In parts 1 through 3 of this series, I described how Multi-Stage Continuous Integration can be used at a team and multiple-team level. In this post, I will describe how Multi-Stage CI can also encompass other development stages.
The Development Hierarchy
So far, we’ve split the mainline up into a hierarchy of branches. Each developer has their own workspace and is part of a team, each team has its own branch, and each team branch is based on and merges back to an integration branch, which may be the mainline. Sometimes work is organized at a feature level instead of at a team level. For simplicity, I’ll just refer to teams. Each part of the hierarchy corresponds to a stage of development. This hierarchy enables multiple parallel development pipelines where changes move from a low level of maturity to a higher level of maturity and the work in the parallel pipelines is continuously integrated.
We’ve covered three stages of development: individual developer coding, team integration, and full project integration. But there are many more stages in a typical project lifecycle, even when you are doing Agile development. Traditionally, the stages of the lifecycle occur in several different places including project plans, the SCM system, and the issue tracking system. This adds development stages such as: code reviewed, system tested, UAT passed, demoed, etc. Each of these stages can be added as a branch to your branch hierarchy.
When using Multi-Stage CI, unlike the typical use of branches, changes do not linger on a branch any longer than required to pass through the stage that branch is associated with. The difference between any given branch and its parent in the hierarchy cycles rapidly between almost nothing and nothing. The goal is to push changes through the hierarchy as rapidly as possible.
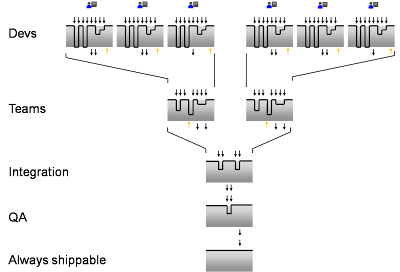
When working within a development hierarchy, the impact of any given change is limited in scope. If there are 4 members on a team, then only 3 other people are affected when a change is merged into the team branch. Because changes are made on the team branch only when the developer has things working in their own version, changes at the team level are made less frequently and have a lower probability of destabilizing the build. Once the team branch is considered stable, changes are then merged into an integration branch which consolidates the work for multiple teams. Again, changes are made less frequently and have a lower probability of destabilizing the build. Thus, the graph at the integration level shows fewer changes and the changes are smaller. As you proceed towards the root of the hierarchy, changes are less frequent and less likely to destabilize the build until finally you reach the root where you have code that is always shippable.
Getting Started
Getting to Multi-Stage CI takes time, but is well worth the investment. The first step is to implement Continuous Integration somewhere in your project. It really doesn’t matter where. For a recommendation on an excellent book on Continuous Integration, see the bibliography. The next step is to implement team or feature based CI. Once you have that working, consider automating the process. For instance, you can set things up such that once CI passes for a stage, it automatically merges the changes to the next level in the hierarchy. This keeps changes moving quickly and paves the way for easily adding additional development stages.
I’ve seen Multi-Stage Continuous Integration successfully implemented in many shops and every time the developers say something like: “I never realized how many problems were a result of doing mainline development until they disappeared.”
Next: It is Better to Find Customer Reported Problems As Soon As Possible
The Development Hierarchy
So far, we’ve split the mainline up into a hierarchy of branches. Each developer has their own workspace and is part of a team, each team has its own branch, and each team branch is based on and merges back to an integration branch, which may be the mainline. Sometimes work is organized at a feature level instead of at a team level. For simplicity, I’ll just refer to teams. Each part of the hierarchy corresponds to a stage of development. This hierarchy enables multiple parallel development pipelines where changes move from a low level of maturity to a higher level of maturity and the work in the parallel pipelines is continuously integrated.
We’ve covered three stages of development: individual developer coding, team integration, and full project integration. But there are many more stages in a typical project lifecycle, even when you are doing Agile development. Traditionally, the stages of the lifecycle occur in several different places including project plans, the SCM system, and the issue tracking system. This adds development stages such as: code reviewed, system tested, UAT passed, demoed, etc. Each of these stages can be added as a branch to your branch hierarchy.
When using Multi-Stage CI, unlike the typical use of branches, changes do not linger on a branch any longer than required to pass through the stage that branch is associated with. The difference between any given branch and its parent in the hierarchy cycles rapidly between almost nothing and nothing. The goal is to push changes through the hierarchy as rapidly as possible.

When working within a development hierarchy, the impact of any given change is limited in scope. If there are 4 members on a team, then only 3 other people are affected when a change is merged into the team branch. Because changes are made on the team branch only when the developer has things working in their own version, changes at the team level are made less frequently and have a lower probability of destabilizing the build. Once the team branch is considered stable, changes are then merged into an integration branch which consolidates the work for multiple teams. Again, changes are made less frequently and have a lower probability of destabilizing the build. Thus, the graph at the integration level shows fewer changes and the changes are smaller. As you proceed towards the root of the hierarchy, changes are less frequent and less likely to destabilize the build until finally you reach the root where you have code that is always shippable.
Getting Started
Getting to Multi-Stage CI takes time, but is well worth the investment. The first step is to implement Continuous Integration somewhere in your project. It really doesn’t matter where. For a recommendation on an excellent book on Continuous Integration, see the bibliography. The next step is to implement team or feature based CI. Once you have that working, consider automating the process. For instance, you can set things up such that once CI passes for a stage, it automatically merges the changes to the next level in the hierarchy. This keeps changes moving quickly and paves the way for easily adding additional development stages.
I’ve seen Multi-Stage Continuous Integration successfully implemented in many shops and every time the developers say something like: “I never realized how many problems were a result of doing mainline development until they disappeared.”
Next: It is Better to Find Customer Reported Problems As Soon As Possible
Tuesday, January 15, 2008
Reducing the Risk of Producing a Hotfix
Let's say there is a problem reported in the field which requires a hotfix. Well, if you are doing traditional software development, you can't exactly ask the customer to wait until you finish your current release. And if you were to put out a fix for them using your main development process, that would probably take too long too. So, you have a hotfix development process. By definition, this is a development process which is not used for regular development and it is not used very often (so one would hope).
As a result, you have one process for regular development and one process for hotfixes because your regular development process takes just too darn long. That means that when you most need for things to go smoothly you are going to use the process which is the least practiced and probably also something that only a handful of folks know how to do or are allowed to do. What's wrong with this picture?
The solution is to get the path from deciding to make a change and being able to deliver that same change as short as reasonably possible. If the "overhead" from start to finish for a hotfix is 4 hours, then any development task should take you no more than the overhead plus however long it takes you to write the code and the associated tests. All development tasks should follow this same streamlined process, not by cutting out truly necessary steps, but by ruthlessly removing steps that add no real value and automating as many of the remaining steps as possible.
Once you have a sufficiently small overhead, then you really only need one development process which you use for both regular development and hotfixes! Since it is the same process, everybody is practiced in your hotfix process and everybody has experience with doing it. This will reduce risk and increase confidence in the results.
In practice, there will probably be at least two differences. It is unlikely that anyone needing a hotfix will want to take the risk associated with taking any changes other than the hotfix, no matter how ready for release you say those other changes are. So, you will need to develop the fix against the release that the customer is using. You will probably also deliver the fix using a slightly different path than the usual. However, the closer you get to just these two differences, the better off you will be.
There is a shortcut you can take on the way to getting to a single process. You can refactor your regular process such that you act like every development task is a hotfix, and then do the rest of the process in a second stage. For instance, if you normally do a subset of your full test cycle for hotfixes, then always do that subset first during regular development.
For some software projects, getting the full test cycle down to a short time frame will be impossible or impractical. In this case, refactoring to have the first stage be the same as the hotfix process is still recommended and keeps you focused on keeping the second stage as small as possible.
As a result, you have one process for regular development and one process for hotfixes because your regular development process takes just too darn long. That means that when you most need for things to go smoothly you are going to use the process which is the least practiced and probably also something that only a handful of folks know how to do or are allowed to do. What's wrong with this picture?
The solution is to get the path from deciding to make a change and being able to deliver that same change as short as reasonably possible. If the "overhead" from start to finish for a hotfix is 4 hours, then any development task should take you no more than the overhead plus however long it takes you to write the code and the associated tests. All development tasks should follow this same streamlined process, not by cutting out truly necessary steps, but by ruthlessly removing steps that add no real value and automating as many of the remaining steps as possible.
Once you have a sufficiently small overhead, then you really only need one development process which you use for both regular development and hotfixes! Since it is the same process, everybody is practiced in your hotfix process and everybody has experience with doing it. This will reduce risk and increase confidence in the results.
In practice, there will probably be at least two differences. It is unlikely that anyone needing a hotfix will want to take the risk associated with taking any changes other than the hotfix, no matter how ready for release you say those other changes are. So, you will need to develop the fix against the release that the customer is using. You will probably also deliver the fix using a slightly different path than the usual. However, the closer you get to just these two differences, the better off you will be.
There is a shortcut you can take on the way to getting to a single process. You can refactor your regular process such that you act like every development task is a hotfix, and then do the rest of the process in a second stage. For instance, if you normally do a subset of your full test cycle for hotfixes, then always do that subset first during regular development.
For some software projects, getting the full test cycle down to a short time frame will be impossible or impractical. In this case, refactoring to have the first stage be the same as the hotfix process is still recommended and keeps you focused on keeping the second stage as small as possible.
Saturday, January 05, 2008
Frequent Releases Do Not Mean Frequent Upgrades
[Note: this is a repost from my temporary WordPress Blog]
A very common objection to Agile Development is that customers don’t want frequent releases. First, Agile Development does not require frequent releases. The benefit of realizing ROI faster comes from frequent releases, but that is just one of the primary benefits. But let’s look at the objection that customers don’t want frequent releases.
Guess what? It’s true. Customers don’t want frequent releases. You can read an example of this here (thanks to Soon Hui). But it doesn’t matter! Let’s take a look at the example where you only have a single customer, for instance your application is for in-house use. Now the choice is up to them which release to take and when to take it. Keep in mind that a requirement for frequent releases is that the quality of those releases needs to be up to your regular standards. Releasing frequently does not give you a license to release poor quality software! And whether that single internal customer takes that release or not, they can also take a look at it and give you their feedback.
In the case of multiple customers, the important point to remember is that there are multiple customers! You can’t think of all of your customers as being a single entity. Your customers don’t take all of your releases when you release them, no matter how frequently or infrequently you produce new releases. At AccuRev, we’ve had customers that stayed back on 2 year old and even 3 year old releases, despite the fact that bugs they had reported had been fixed and features they had asked for had been added.
Basically, the frequency of releases is completely disconnected from the frequency of customer uptake of releases. The exception is when the customer has an urgent need. In that case, you had better be able to attend to that need quickly. Since that is the case anyway, again there is no connection between the frequency of regular releases and customer uptake of releases.
Customers take new releases when there is a good reason to do so. Usually, that is when the delta between where they are and the current release is big enough to warrant the disruption and they have a place in their schedule to put it. As the provider, this window is pretty much unpredictable for you. When that time comes, the customer will take your most recent release or perhaps the one before that under the assumption that more is known about the state of the older release. If you have more than one customer, the chances that your entire customer base is ready to take a release when you release it is pretty low.
When you have multiple customers, those that have a good reason to take the release will do so, and those that do not will not. One of the advantages of frequent releases is that there is a high likelihood that one of your customers will move to it fairly soon after the release, thus giving you an opportunity to gather feedback right away.
If you are just not ready to release frequently, that’s ok. Instead, use short iterations and just go on to the next iteration instead of releasing it. You can still get most of the feedback related benefits of Agile Development by having folks take a look at a demo of the new iteration and avoid the risk of disrupting your customer base with an iteration that is not yet ready for release.
Multi-Stage Continuous Integration Part III
In Part I and Part II I discussed the problems associated with Continuous Integration when combined with mainline development. In this part I’ll discuss a solution: Multi-Stage Continuous Integration.
Have Some Self Integrity
As an individual developer, you practice two simple best practices which you probably don’t even think about any more.
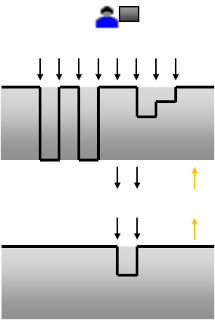
While you make frequent changes to your workspace which means its stability goes up and down rapidly, you only check-in your changes when you feel like you’ve done enough testing of those changes that you've sufficiently reduced the risk of impacting the stability of the mainline. Second, you only update your workspace when you are at a point that you don’t mind taking whatever the impact is from other people’s changes. These two simple practices act as buffers which protect other people from the chaos of your workspace while you prepare to check-in and protect you from problems that other people may have introduced during that same period. It also produces a variant version of the software for each developer which must all be integrated together. The longer you put off this integration, the more painful it will eventually be. Thus the need for Continuous Integration.
When you as an individual are working on a change, you are often changing several files and a change in one file often requires a corresponding change in another file. While it may seem like a bit of a trivial case, you can think of this process as self-integration. The reason that you work on those files on your own instead of having several people work on it is because the tightly coupled nature of the changes requires a single person.
It's All for One and One for All
The next level of coupling is at the team level. There are many reasons why a set of changes are tightly coupled, for instance there may be a large feature that can be worked on by more than one person. As a team works on a feature, each individual needs to integrate their changes with the changes made by the other people on their team. For the same reasons that an individual works in temporary isolation, it makes sense for teams to work in temporary isolation. When a team is in the process of integrating the work of its team members, it does not need to be disrupted by the changes from other teams and conversely, it would be better for the team not to disrupt other teams until they have integrated their own work. But just as is the case with the individual, there should be continuous integration at the team level, but then also between the team and the mainline.
Multi-Stage Continuous Integration
So, how can we take advantage of the fact that some changes are at an individual level and others are at a team level while still practicing Continuous Integration? By implementing Multi-Stage Continuous Integration of course! For now, I’ll just cover the basics, but in a future post I’ll go into more detail and cover advanced topics as well.
For Multi-Stage CI, each team gets its own branch. I know, you cringe at the thought of per-team branching and merging, but that’s probably because you are thinking of branches that contain long-lived changes. We’re not going to do that here.
There are two phases that the team goes through, and the idea is to go through each of them as rapidly as is practical. The first phase is the same as before. Each developer works on their own task. As they make changes, CI is done against that team’s branch. If it succeeds, great. If it does not succeed, then that developer (possibly with help from her teammates) fixes the branch. When there is a problem, only that team is affected, not the whole development effort.
On a frequent basis, the team will decide to go to the second phase: integration with the mainline. In this phase, the team does the same thing that an individual would do in the case of mainline development. The team’s branch must have all changes from the mainline merged in (the equivalent of a workspace update), there must be a successful build and all tests must pass. Keep in mind that integrating with the mainline will be easier than usual because only pre-integrated features will be in it, not features-in process. Then, the team’s changes are merged into the mainline which will trigger a mainline CI. If that passes, then the team goes back to the first phase where individual developers work on their own tasks. Otherwise, the team works on getting the mainline working again, just as though they were an individual working on mainline.
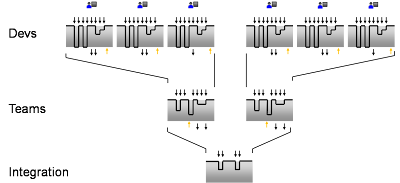
Multi-Stage CI allows for a high degree of integration to occur in parallel while vastly reducing the scope of integration problems. It takes individual best practices that we take for granted and applies them to the team level.
With Agile, you don’t have the luxury of doing big-bang integration at the end of your development cycle, but when you are scaling Agile beyond a single small collocated team, mainline CI doesn’t mix well with short iterations. Multi-Stage CI solves both problems.
Per-team CI is one form of Multi-Stage CI. In the next part of this series, I’ll introduce some more opportunities for Multi-Stage CI.
Next: Advanced Multi-Stage Continuous Integration
Have Some Self Integrity
As an individual developer, you practice two simple best practices which you probably don’t even think about any more.

While you make frequent changes to your workspace which means its stability goes up and down rapidly, you only check-in your changes when you feel like you’ve done enough testing of those changes that you've sufficiently reduced the risk of impacting the stability of the mainline. Second, you only update your workspace when you are at a point that you don’t mind taking whatever the impact is from other people’s changes. These two simple practices act as buffers which protect other people from the chaos of your workspace while you prepare to check-in and protect you from problems that other people may have introduced during that same period. It also produces a variant version of the software for each developer which must all be integrated together. The longer you put off this integration, the more painful it will eventually be. Thus the need for Continuous Integration.
When you as an individual are working on a change, you are often changing several files and a change in one file often requires a corresponding change in another file. While it may seem like a bit of a trivial case, you can think of this process as self-integration. The reason that you work on those files on your own instead of having several people work on it is because the tightly coupled nature of the changes requires a single person.
It's All for One and One for All
The next level of coupling is at the team level. There are many reasons why a set of changes are tightly coupled, for instance there may be a large feature that can be worked on by more than one person. As a team works on a feature, each individual needs to integrate their changes with the changes made by the other people on their team. For the same reasons that an individual works in temporary isolation, it makes sense for teams to work in temporary isolation. When a team is in the process of integrating the work of its team members, it does not need to be disrupted by the changes from other teams and conversely, it would be better for the team not to disrupt other teams until they have integrated their own work. But just as is the case with the individual, there should be continuous integration at the team level, but then also between the team and the mainline.
Multi-Stage Continuous Integration
So, how can we take advantage of the fact that some changes are at an individual level and others are at a team level while still practicing Continuous Integration? By implementing Multi-Stage Continuous Integration of course! For now, I’ll just cover the basics, but in a future post I’ll go into more detail and cover advanced topics as well.
For Multi-Stage CI, each team gets its own branch. I know, you cringe at the thought of per-team branching and merging, but that’s probably because you are thinking of branches that contain long-lived changes. We’re not going to do that here.
There are two phases that the team goes through, and the idea is to go through each of them as rapidly as is practical. The first phase is the same as before. Each developer works on their own task. As they make changes, CI is done against that team’s branch. If it succeeds, great. If it does not succeed, then that developer (possibly with help from her teammates) fixes the branch. When there is a problem, only that team is affected, not the whole development effort.
On a frequent basis, the team will decide to go to the second phase: integration with the mainline. In this phase, the team does the same thing that an individual would do in the case of mainline development. The team’s branch must have all changes from the mainline merged in (the equivalent of a workspace update), there must be a successful build and all tests must pass. Keep in mind that integrating with the mainline will be easier than usual because only pre-integrated features will be in it, not features-in process. Then, the team’s changes are merged into the mainline which will trigger a mainline CI. If that passes, then the team goes back to the first phase where individual developers work on their own tasks. Otherwise, the team works on getting the mainline working again, just as though they were an individual working on mainline.

Multi-Stage CI allows for a high degree of integration to occur in parallel while vastly reducing the scope of integration problems. It takes individual best practices that we take for granted and applies them to the team level.
With Agile, you don’t have the luxury of doing big-bang integration at the end of your development cycle, but when you are scaling Agile beyond a single small collocated team, mainline CI doesn’t mix well with short iterations. Multi-Stage CI solves both problems.
Per-team CI is one form of Multi-Stage CI. In the next part of this series, I’ll introduce some more opportunities for Multi-Stage CI.
Next: Advanced Multi-Stage Continuous Integration
Friday, January 04, 2008
Do It Yourself Agile
[Last updated: Oct 1, 2009]
This is an evolving web-only book for the Agile DIY'er. A downloadable version, with more content (180+ pages), is also available.
Table of Contents
Introduction
Agile in a Nutshell
Traditional Development Scenario
Agile Development Scenario
Primary vs Secondary Benefits
Agile Development, What's in it for Me?
Reinvest in Your Engine by Improving the Work Environment
Your Development Process is Part of Your Work Environment
A Quick Summary of the Benefits of Adopting Agile
The Problems With Traditional Development
Dev Team Having Performance Problems? Try Niagra!
The Chinese Finger Trap of Traditional Development
The Chinese Finger Trap: Architecture, Development, and QA
Short Iterations
Unconciously Agile
The Agile Waterfall
Sustainable Pace: Supply vs. Demand
The Usability of Short Iterations
Process Perspective
There is no Bug. It is Not The Bug That Bends, it is Only Yourself
Apply Elegant Architecture to Your Dev Team
How Agile Solves Problems
Agile Lifecycle
Agile Product Management
The Role of Defect Management in Agile Development
Designing Software is the Same as Predicting the Future
The Simplest Thing That Could Possibly Work
The "Faberge Egg" Widget
Frequent Releases Improve Code Quality Faster
The Role of QA in an Agile Project
Integration
Multi-Stage Continuous Integration
Advanced Multi-Stage Continuous Integration
Releasing
It's Better to Find Customer Reported Problems ASAP
Customers Don't Want Frequent Releases
Tuning the Frequency of Your Release
Adopting Agile
Stage 1: Preparing for the Transition to Agile
Stage 2: Establishing a Natural Rhythm
Complementary Practices
Do You Need a Standup Meeting?
Appendix A
Agile Case Study: Litle and Co.
The Iterative Design of a Transforming Lego Car
Bibliography
More to come!
This is an evolving web-only book for the Agile DIY'er. A downloadable version, with more content (180+ pages), is also available.
Table of Contents
Introduction
Agile in a Nutshell
Traditional Development Scenario
Agile Development Scenario
Primary vs Secondary Benefits
Agile Development, What's in it for Me?
Reinvest in Your Engine by Improving the Work Environment
Your Development Process is Part of Your Work Environment
A Quick Summary of the Benefits of Adopting Agile
The Problems With Traditional Development
Dev Team Having Performance Problems? Try Niagra!
The Chinese Finger Trap of Traditional Development
The Chinese Finger Trap: Architecture, Development, and QA
Short Iterations
Unconciously Agile
The Agile Waterfall
Sustainable Pace: Supply vs. Demand
The Usability of Short Iterations
Process Perspective
There is no Bug. It is Not The Bug That Bends, it is Only Yourself
Apply Elegant Architecture to Your Dev Team
How Agile Solves Problems
Agile Lifecycle
Agile Product Management
The Role of Defect Management in Agile Development
Designing Software is the Same as Predicting the Future
The Simplest Thing That Could Possibly Work
The "Faberge Egg" Widget
Frequent Releases Improve Code Quality Faster
The Role of QA in an Agile Project
Integration
Multi-Stage Continuous Integration
Advanced Multi-Stage Continuous Integration
Releasing
It's Better to Find Customer Reported Problems ASAP
Customers Don't Want Frequent Releases
Tuning the Frequency of Your Release
Adopting Agile
Stage 1: Preparing for the Transition to Agile
Stage 2: Establishing a Natural Rhythm
Complementary Practices
Do You Need a Standup Meeting?
Appendix A
Agile Case Study: Litle and Co.
The Iterative Design of a Transforming Lego Car
Bibliography
More to come!
Subscribe to:
Posts (Atom)